Cloud Cost Optimisation: Smart Strategies for a Leaner Stack
The cloud got expensive. Now what?
Cloud computing was supposed to make everything easier: scalable, flexible, and cost-efficient. But these days, the cloud bill is starting to tell a different story for companies. What began as a way to avoid massive upfront infrastructure costs has quietly morphed into a growing operational burden. Teams are seeing cloud spend spike with little clarity on where the costs are coming from or how to control them.
Keep reading to learn more about what’s behind rising cloud costs, and how cloud cost optimisation strategies can help you stay lean, flexible, and in control.
Why Cloud Costs Are Surging in 2025
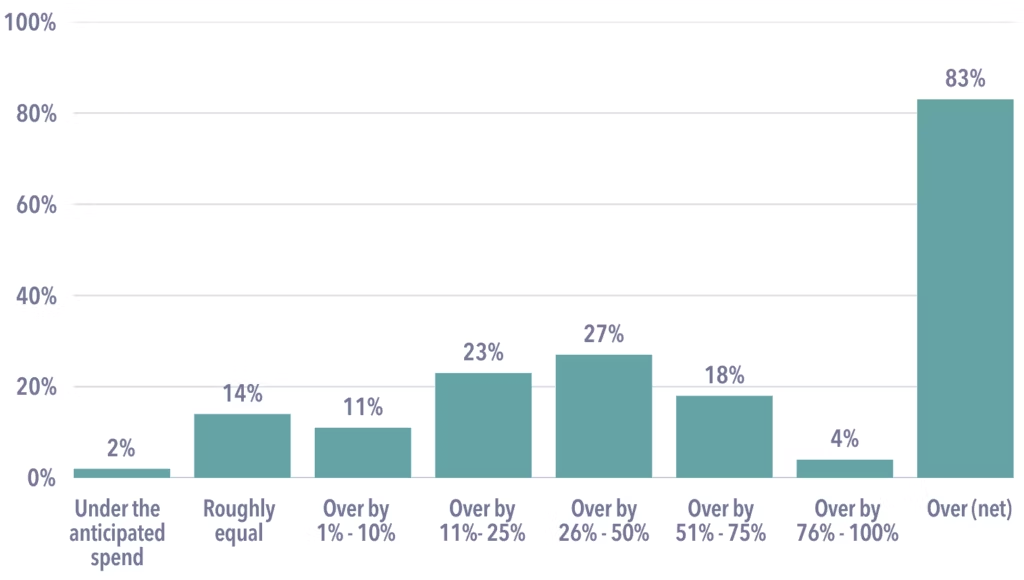
Source: Azul 2025 CIO Survey
According to one study, 83% of CIOs surveyed said that cloud infrastructure has become a significant cost management challenge. As more workloads shift to cloud-native environments, organisations are realising that cloud pricing trends are leaning towards flexibility, not predictability.
So what’s driving the increased costs?
AI and data-intensive workloads
Machine learning, real-time analytics, and large-scale data processing are putting heavy demand on high-performance compute resources. These workloads rely on GPU-intensive instances or distributed pipelines that rack up costs quickly, especially when not scaled efficiently.
Inefficient resource scaling
Many teams still use manual provisioning or default autoscaling configurations, which often result in overallocated infrastructure. When instances are consistently underutilised, the excess capacity translates directly into wasted spend.
Vendor pricing complexity
Cloud providers have introduced increasingly granular billing models, with costs tied to compute, storage, data egress, regional access, and more. Over time, even small adjustments in pricing tiers or service configurations lead to noticeable increases in monthly spend.
Hidden operational gaps
Without clear monitoring, tagging, or cost attribution, cloud environments become opaque. That lack of visibility makes it difficult to connect infrastructure usage with business value, and easy for spending to spiral out of control.
Common Sources of Cloud Waste
At DO OK, we’ve worked with companies across multiple industries that moved to the cloud with good intentions, but found themselves grappling with unexpected waste that eroded their budgets.
Here are some of the most common culprits:
– Idle or unused instances: development environments left running overnight, forgotten test clusters, or auto-provisioned resources with no recent activity
– Overprovisioning: allocating compute or storage capacity “just in case”, then paying for headroom that never gets used
– Zombie infrastructure: detached volumes, orphaned snapshots, or deprecated services that weren’t fully cleaned
– Poorly configured autoscaling: autoscaling rules not tuned for real workload patterns, scaling up too quickly or not scaling down at all
– Data egress and cross-region replication: transferring data between regions or out of your cloud provider, especially in hybrid or multi-cloud setups
In all these cases, the root issue is visibility. Without effective metrics, tagging, and monitoring, it’s hard to see waste, let alone fix it. That’s why our cloud audits focus first on making usage transparent. Once you can see the inefficiencies, you can start reclaiming value.
FinOps: A Smarter Way to Manage Cloud Spending
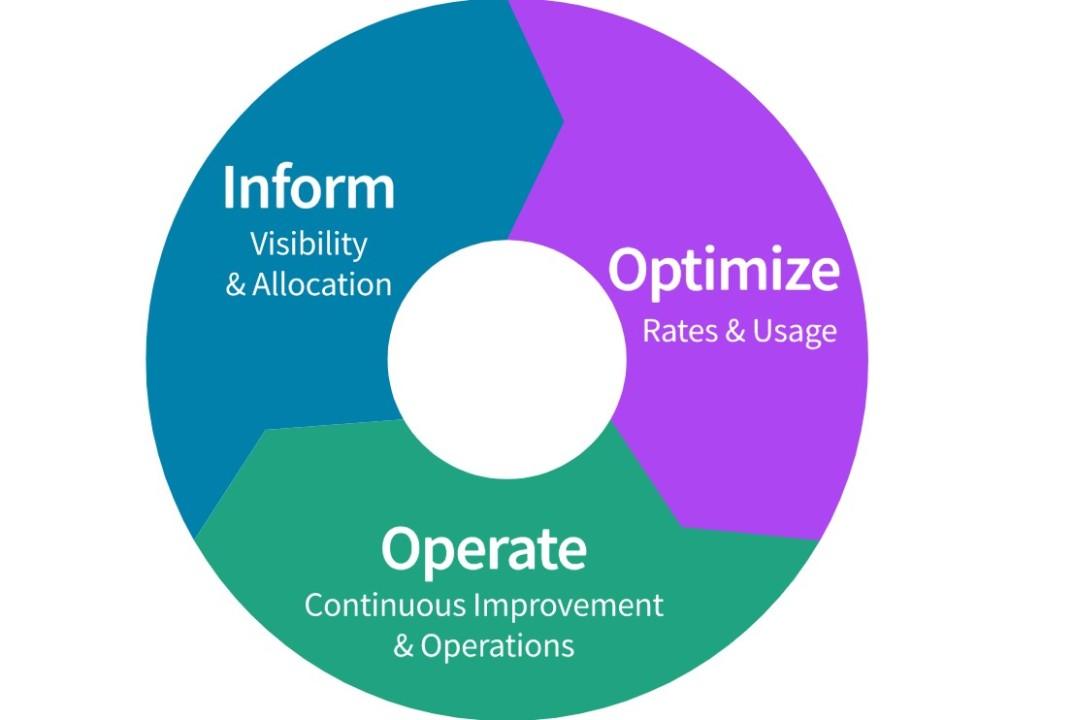
Source: FinOps.org FinOps Framework
Many organisations watching their cloud costs balloon are realising that optimisation is less of a technical issue and more of a cultural and operational one. That’s when leveraging FinOps can help create the flexibility teams need to stay agile.
FinOps, short for Cloud Financial Operations, is a cross-functional discipline that brings together engineering, finance, and operations teams to collaborate on cloud cost management. Unlike traditional cloud cost control approaches that happen after the fact, FinOps is proactive, baking cost awareness into everyday decisions.
FinOps helps answer three primary questions:
1. Where is our money going?
2. Is that spend aligned with business value?
3. What can we do about it, now and long term?
Developers and product teams can no longer treat cloud infrastructure as a blank cheque, and FinOps for cloud operations creates processes and shared language to make cost a first-class metric, just like performance or uptime.
According to Deloitte, FinOps practices have helped many companies to achieve tangible cloud cost savings:
- – Airbnb: US$63.5 million
- – Sky Group: US$1.5 million, then US$3.8 million the following year
- – The Home Depot: tens of millions of dollars YoY
– Lyft: cut cloud costs per ride by 40% in six months
– WPP: US$2 million after 3 months and 30% annual cost reduction
Other practical benefits of FinOps for cloud teams include more accurate cloud budget planning, real-time visibility into spend by team or product, and shared accountability across departments. Mature FinOps practices can help organisations automate savings, reduce waste, and embed cost accountability at the team level.
Practical Strategies for Cloud Cost Optimisation
Once you’ve established visibility and a FinOps mindset, the next step is putting cost optimisation into practice. Many effective tactics are simple and provider-agnostic:
1. Use reserved and spot instances strategically
Buying reserved instances can significantly reduce costs (up to 72% in some cases) for predictable workloads. For more flexible compute, consider spot instances (AWS), preemptible VMs (GCP), or low-priority VMs (Azure). These offer steep discounts in exchange for limited availability, ideal for batch processing or fault-tolerant tasks.
2. Rightsize cloud resources
Oversized instances are a top source of waste. Use tools like AWS Compute Optimiser or GCP’s Recommender to assess CPU, memory, and storage usage, and then match instance size to actual workload demand to improve cloud resource utilisation. This approach to rightsizing cloud resources can cut spend by 20-40% without affecting performance.
3. Automate shutdowns for dev/test environments
Non-production environments regularly run 24/7 by default. By automating scheduled shutdowns overnight and on weekends & bank holidays, teams can save thousands annually without any impact on delivery timelines.
4. Enable autoscaling (but tune it)
Autoscaling is only effective if it’s tuned to real usage patterns. Review thresholds, cooldown periods, and scaling policies to avoid overreacting to short-term spikes or lagging behind traffic surges.
5. Leverage cost monitoring tools
Native tools like AWS Cost Explorer, Azure Cost Management, and GCP Cloud Billing Reports provide a baseline. For more advanced tracking, platforms like CloudHealth, Kubecost, or CAST AI can surface granular insights and automate savings recommendations.
The trick with applying any of these tactics is to make them habitual, not one-time tweaks. A leaner stack requires regular reviews, forecasting, and iteration.
Should You Switch Providers or Go Multi-Cloud?
When clients come to us frustrated by high cloud costs, one of the first questions they ask is whether they should switch providers. In our experience, moving from AWS to GCP or Azure (or vice versa) rarely delivers meaningful savings on its own.
Yes, each provider does feature different pricing models and incentives. A thorough cloud service provider comparison shows that AWS spot instances can be cost-effective for certain workloads, while GCP’s preemptible VMs might offer better rates for short-lived tasks. But without a broader architectural change, you’re likely just shifting complexity, not eliminating cost.
We also see growing interest in multi-cloud strategies driven by a desire for pricing leverage or redundancy, which can work for some teams. But it also introduces new challenges: more tools to manage, more vendor-specific knowledge to maintain, and more room for inefficiency if governance isn’t tight.
We advise clients to focus first on optimising the cloud they already use. Switching providers or expanding to multi-cloud can be effective, but only when it supports a clear technical or business goal, not as a reaction to sticker shock.
When Cloud Isn’t the Right Choice
While cloud infrastructure offers flexibility and speed, we’ve seen cases where it simply doesn’t make sense, especially when cost predictability and control are top priorities.
Some workloads are steady, high-throughput, and don’t benefit from the elasticity cloud provides. In those cases, we’ve helped clients evaluate bare-metal or flat-rate hosting solutions that offer better long-term value. These setups can reduce both infrastructure and operational costs.
We’ve also worked with teams in highly regulated industries where compliance or data sovereignty requirements make full control over physical infrastructure non-negotiable. And in certain performance-sensitive environments, like real-time systems or edge deployments, the cloud’s abstraction can introduce unwanted latency or limitations.
Part of our job is helping clients understand when it supports their goals, and when it doesn’t. Choosing cloud shouldn’t be automatic. Sometimes, the smartest architecture is the simplest one.
The Role of Tooling and Automation in Cost Control
Controlling cloud spend at scale today demands automation; relying on dashboards and manual reviews just won’t cut it any more. As infrastructure becomes more dynamic (and costly), organisations need systems that can detect inefficiencies and respond in real time.
Most providers offer native tools to monitor and manage costs: AWS has Cost Explorer and Trusted Advisor, Azure offers Cost Management, and GCP provides Billing Reports and recommendations. These are useful starting points, but they can lack the granularity or automation needed for sustained optimisation.
Third-party tools like Kubecost, CAST AI, and CloudHealth go further: analysing container efficiency, suggesting right-sizing actions, or automating cleanups based on policy.
Visibility is important, but what teams need is actionability. When cost thresholds trigger alerts, unused resources should shut down automatically, and tags should inform transparently across teams. Optimisation becomes part of the system. Automation turns cloud cost control into a continuous process in fast-updating cloud environments.
Building a Cost-Conscious Cloud Culture
Without shared ownership and ongoing discipline, even well-architected infrastructure can drift into inefficiency. Cost control should be embedded into how teams build and deploy, beyond just how they review invoices.
This starts with transparency. Engineers, product leads, and operations teams need visibility into how their choices impact spending. That means integrating cost metrics into dashboards, tagging resources clearly, and reviewing spend as part of regular delivery cycles.
It also takes accountability. When teams share responsibility for cloud budgets, optimisation becomes a collaborative habit, not a reactive fix. The most resilient organisations aren’t the ones spending the least; they’re the ones spending with intentionality.
At DO OK, we help teams do just that. We work with you to guide product development through tailored discovery workshops, cloud audits, and smart architecture choices for software and IoT MVP development that support your business goals long term.
Ready to build a leaner, smarter cloud stack? Contact us and find out how our custom software development services can help support your next phase of cloud cost optimisation.