Trello Stats – Track Productivity in a Simple Way
Tracking teams’ productivity has always been a challenge. The Trello tool helps organize work and complete tasks efficiently. However, understanding how to interpret the completed cards is crucial for assessing your team’s efficiency. In this article, I will delve into the concept behind Trello Stats, discussing the challenges I faced as a front-end developer and sharing the lessons I learned along the way.
A few months into my role as a front-end web developer trainee at DO OK, one of my colleagues in our workspace shared an exciting idea for a web application – Trello Stats. After discussing it with our team leader, we decided to collaborate on bringing this idea to life.
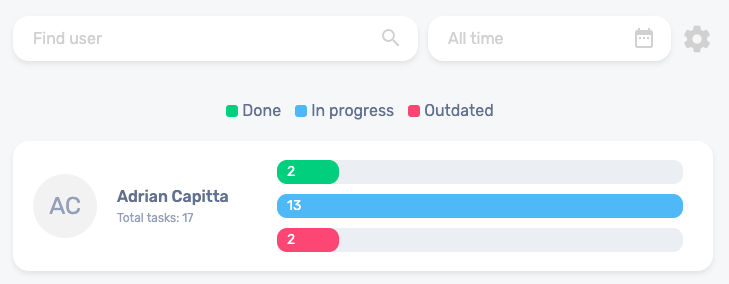
What is Trello Stats?
Trello Stats essentially serves as a standalone extension of the Trello website. Its primary purpose is to allow users to track their team’s productivity by providing straightforward data on each user’s ongoing, completed, and overdue tasks. For those who might not be familiar with Trello, it’s a web application designed to help individuals and teams organize their work through boards. These boards consist of lists containing small notes, descriptions, or tasks known as cards. You can further enhance these cards by adding due dates, assigning specific tasks to users, marking tasks as complete, and more.
However, my colleague recognized a gap in Trello’s functionality. There wasn’t a built-in way to track metrics such as the number of tasks completed by each user, the tasks currently in progress, or identifying users who frequently miss deadlines. This is where Trello Stats comes into play. By logging in with your Trello account, you can select a board and access information about each user’s tasks categorized into three groups: done, in progress, and overdue.
Quick research & picking a Tech Stack
After a quick Google search, it became apparent that there were no existing apps that fulfilled our vision for Trello Stats. Existing options were either too complex or didn’t align with our specific goals for the application. Our primary aim was to create something simple and minimalistic, with a strong foundational framework that we could easily expand upon. We wanted to ensure that users could easily dive into the app without any unnecessary complexity.
Without further delay, we decided it was time to start working on it. Initially, we created some basic designs using Adobe XD. Once the design phase was complete, we moved on to selecting our technology stack. After careful consideration, we opted for the MERN stack, which stands for MongoDB, Express.js, React.js, and Node.js. This stack proved to be a well-suited choice for our project’s requirements and goals.
Brainstorming
Since we wanted to have some configuration and filtering through date spans, the first question was, how will the tasks be read and tracked by the system?
Tracking the tasks
The built-in features of Trello, such as task completion and setting deadlines, made the initial development process relatively straightforward. The backend could analyze these values to determine which tasks were completed, outdated, or in progress. However, this was just the beginning, and there were additional scenarios to consider.
One important consideration was the flexibility to accommodate users who preferred a different approach to marking tasks as finished. Some users might prefer to drag completed tasks onto a board they’ve designated as “finished” rather than using Trello’s built-in task completion feature, or they might want to combine both methods. As a result, it was crucial to provide users with this option.
Additionally, another aspect that needed attention was handling cards assigned to a user that were not necessarily tasks but rather notes directed at that user. To address this, the application needed the capability to exclude lists containing such cards from the analysis, ensuring that only actual tasks were considered in the productivity metrics.
Filtering by date
The aspect of filtering tasks by date presented some less obvious considerations. The question arose: should the system primarily consider tasks within a date range based solely on their creation date, or should it also factor in elements like tasks that are due, in progress, or have been completed during the selected time interval?
After some brainstorming and careful deliberation, we concluded that it would be most straightforward and user-friendly to primarily consider tasks based on their creation date. Introducing additional criteria could lead to numerous edge cases and potential confusion. For instance, tasks that were in progress but did not have due dates (since due dates are optional in Trello) might appear in virtually any date range, making it challenging for users to get the most relevant tasks for a specific time frame.
By focusing on the creation date, we aimed to provide users with a clear and consistent way to filter and analyze tasks, ensuring that they would receive the most pertinent information for their desired period.
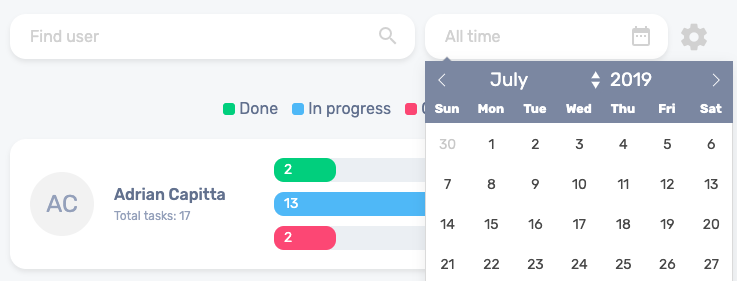
The final solution to tracking the tasks
Ultimately, we’ve decided that the tasks initially will be read by the system. Outdated tasks are returned from the back-end as outdated when they go past their due date without being marked as complete. Finished ones are marked as ended when the user has checked them off. Then the rest is returned as “in progress”.
After that, users should also have the ability to pick custom lists based on their purpose, hence the settings view.
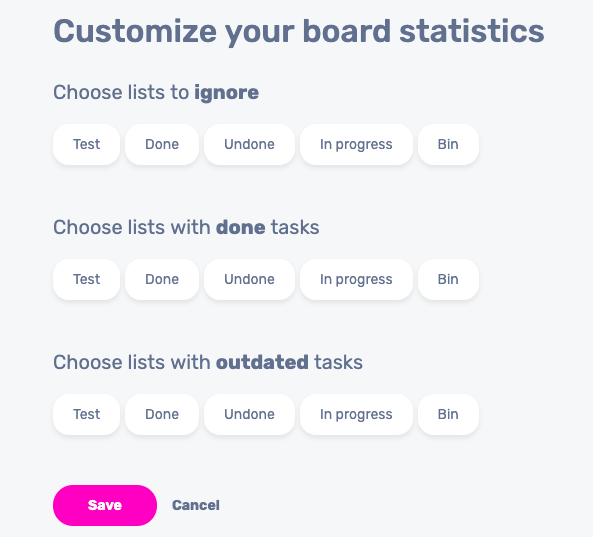
In this situation, settings come down to three categories, where you can pick lists that contain tasks that are either done, or outdated or lists that should be excluded from tracking altogether.
At that point, we have reached the core functionality of Trello Stats.
Experience gained from the development process
One of the aspects I truly appreciate about working at DO OK is the friendly and supportive environment where everyone is willing to help and explain things. As a beginner, this has been immensely beneficial for my learning journey. Throughout this project, I’ve had the opportunity to acquire a considerable amount of knowledge.
Whenever I encountered challenges that could be easily resolved by utilizing external plugins, I embarked on a search for suitable solutions. For instance, the use of the ‘react-flatpack’ plugin provided me with a clean and efficient date picker that was readily adaptable for my project’s needs. I could customize its styling by overwriting predefined classes, which saved a significant amount of time. While understanding the fundamental concepts is essential, it’s also important to recognize when leveraging existing tools can save valuable time, rather than reinventing the wheel repeatedly.
I also came to appreciate the significance of clean code practices. While there’s always room for innovation and refactoring, adhering to established rules and conventions is crucial. This includes naming variables and functions in a way that makes them instantly understandable to anyone, maintaining proper indentation, and organizing imports in a logical order. These details matter, and I hadn’t paid as much attention to them previously due to my limited knowledge and experience. Thanks to feedback from my colleagues during this project, I’ve become more mindful of these aspects, which has contributed to improving the quality of my code.
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand“ – Martin Fowler
The above quote stuck with me throughout the project. If you’d like to go deeper, our post on clean code naming practices covers the conventions that can make the biggest difference in your own coding.
Finally, I had the opportunity to collaborate with my colleague, who crafted the back-end for our software development company. It was immensely satisfying to witness how I could retrieve data from the back end by making requests and observing how all the elements of a web application seamlessly interconnected.
One crucial realization, which may seem evident to many, but was particularly enlightening for me, is that being front-end developers should not confine us solely to that aspect of web development. Front-end developers need to possess a foundational understanding of back-end development and grasp the broader concepts of how computers communicate. Likewise, back-end developers can benefit from understanding front-end principles. This knowledge not only fosters better collaboration and communication within development teams but also provides a more comprehensive perspective on the entire web development process. It enables us to work more effectively as a united team and contributes significantly to our professional growth and versatility.
Again, don’t forget to keep your code clean; it’s essential for your career as a software developer.
Summary
One thing is certain – I had a lot of fun participating in this project. I think the idea behind it is interesting, and it is far from realizing its potential. We’re still at an early phase, and it has its’ core functionalities set. If you’d like to expand on the ideas, or share some suggestions, ideas – feel free to do so, we would love it!
Trello Stats is open-source, and you can contribute to our company’s repo on Github here:
Finally, you can find the full overview of the product on the Trello Stats project page.


